
AI Tools vs Traditional Tools in Bioinformatics- Which one to select?
We find a lot of bioinformatics tools designed to perform a single…

MOCCA- A New Suite to Model cis- regulatory Elements for Motif Occurrence Combinatorics
cis-regulatory elements are DNA sequence segments that regulate gene expression. cis-regulatory elements…

vs_Analysis.py: A Python Script to Analyze Virtual Screening Results of Autodock Vina
The output files obtained as a result of virtual screening (VS) using…

How to search motif pattern in FASTA sequences using Perl hash?
Here is a simple Perl script to search for motif patterns in…

How to read fasta sequences from a file using PHP?
Here is a simple function in PHP to read fasta sequences from…

How to read fasta sequences as hash using perl?
This is a simple Perl script to read a multifasta file as a…

BETSY: A new backward-chaining expert system for automated development of pipelines in Bioinformatics
Bioinformatics analyses have become long and difficult as it involves a large…

Algorithm and workflow of miRDB
As mentioned in the previous article, Micro RNAs (miRNAs) are the short endogenous…
miRBase: Explained
Micro RNAs (miRNAs) are the short endogenous RNAs (~22 nucleotides) and originate…
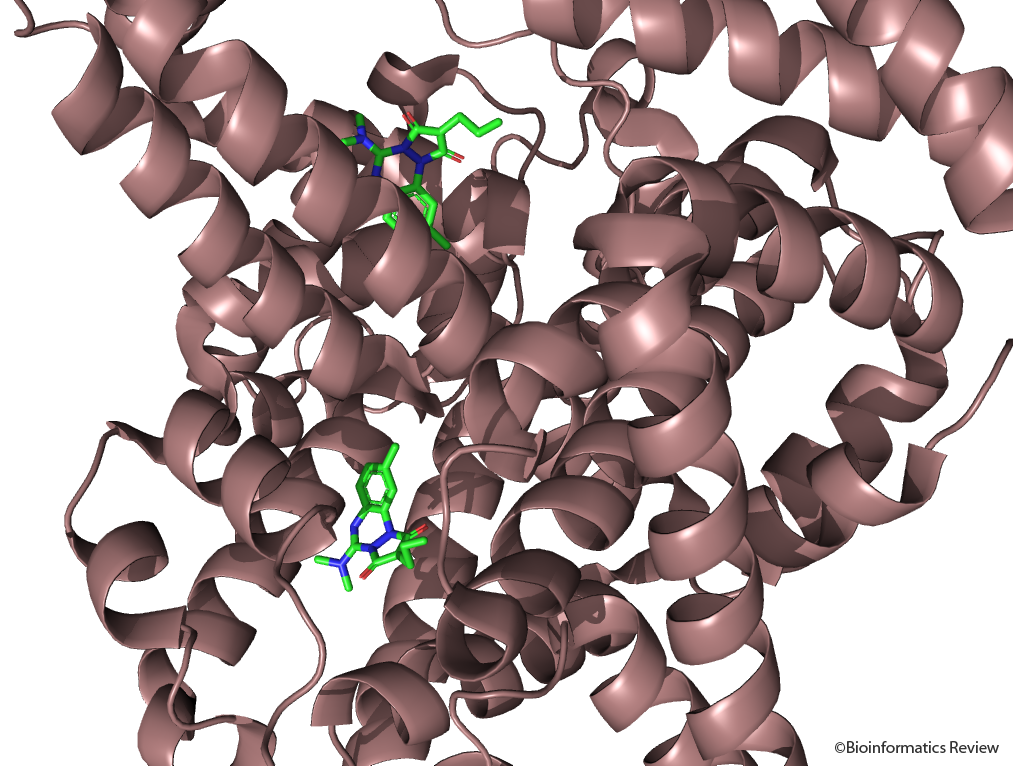
Prediction of biochemical reactions catalyzed by enzymes in humans
There are many biological important enzymes which exist in the human body,…

A new high-level Python interface for MD simulation using GROMACS
The roots of the molecular simulation application can be traced back to…

Machine learning in prediction of ageing-related genes/proteins
Ageing has a great impact on human health, when people's age advance…

Simulated sequence alignment software: An alternative to MSA benchmarks
In our previous article, we discussed different multiple sequence alignment (MSA) benchmarks…

Benchmark databases for multiple sequence alignment: An overview
Multiple sequence alignment (MSA) is a very crucial step in most of…

ab-initio prediction of protein structure: An introduction
We have heard a lot about the ab-initio term in Bioinformatics, which…
Intrinsically disordered proteins’ predictors and databases: An overview
Intrinsically unstructured proteins (IUPs) are the natively unfolded proteins which must be…

An introduction to the predictors of pathogenic point mutations
Single nucleotide variation is a change in a single nucleotide in a…


Role of Information Theory, Chaos Theory, and Linear Algebra and Statistics in the development of alignment-free sequence analysis
Sequence alignment is customary to not only find similar regions among a…

Bioinformatics Challenges and Advances in RNA interference
RNA interference is a post-transcriptional gene regulatory mechanism to down-regulate…